

Harnessing the potential of data has become paramount in today’s technology-driven world. With the advent of observability platforms like FusionReactor, the ability to ingest data from a wide range of sources has become a game-changer. In this blog, we will explore the unparalleled benefits of data ingestion from sources such as Databases, Nginx, Kafka, Docker, IIS, and Machine System Metrics.
Achieving Performance Amplification
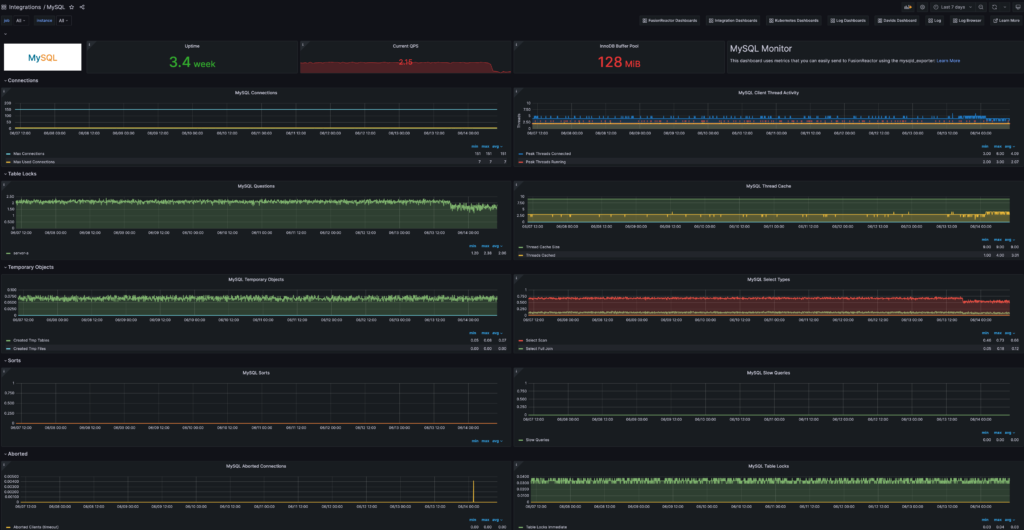
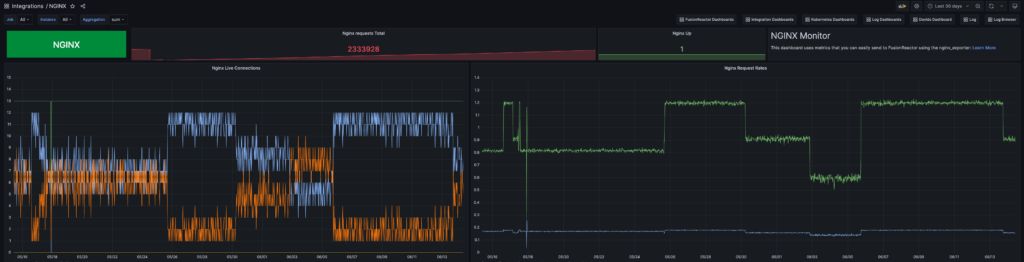
Data ingestion plays a pivotal role in driving performance improvements across various components of your system. By harnessing the power of FusionReactor’s data ingestion capabilities, you can unveil hidden optimization opportunities within your databases, gain insights into web server performance with Nginx, leverage real-time analytics and stream processing with Kafka, monitor containerized applications for enhanced efficiency with Docker, and uncover the veil of IIS for Windows environments. Additionally, by harvesting machine system metrics, FusionReactor enables proactive maintenance and empowers you to optimize resource utilization for better performance and cost efficiency.
Enabling Comprehensive Observability
Data ingestion from diverse sources provides a unified view of your application stack, breaking down silos and bridging the gap between databases, servers, and infrastructure. FusionReactor’s data ingestion capabilities allow you to trace transactions across distributed components, identify patterns and dependencies, providing a comprehensive understanding of your system’s behavior. With FusionReactor, you can correlate data from different sources, gaining valuable insights into your system’s overall health and performance.
Rapid Troubleshooting
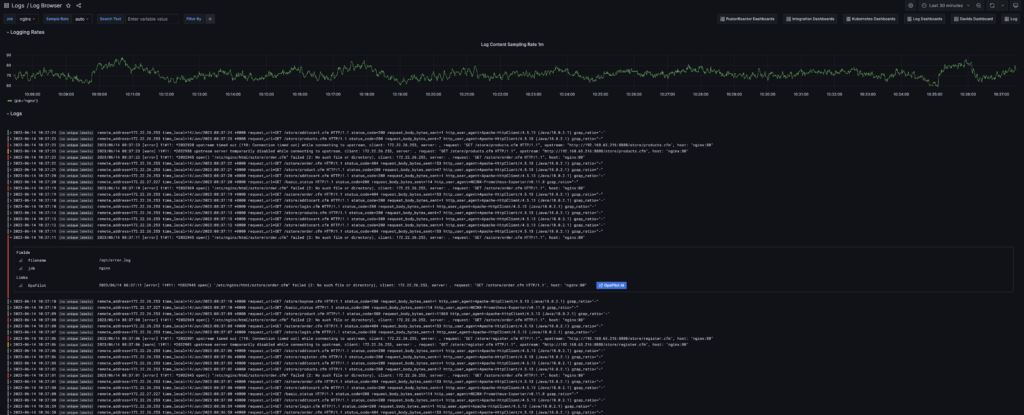
Efficient troubleshooting is crucial for maintaining system reliability. By ingesting data from various sources, FusionReactor empowers you to detect anomalies and performance bottlenecks in real-time, track errors, and handle exceptions effectively. The deep diagnostic capabilities of FusionReactor enable you to dive deep into system behavior, aiding in the rapid identification and resolution of issues.
Optimizing Resource Utilization
With FusionReactor’s data ingestion capabilities, you can optimize resource utilization by identifying resource-intensive processes, understanding workload patterns and demands, and making data-driven capacity planning decisions. By harnessing the insights gained from data ingestion, you can streamline performance, scale with confidence, and right-size your infrastructure for optimal efficiency.
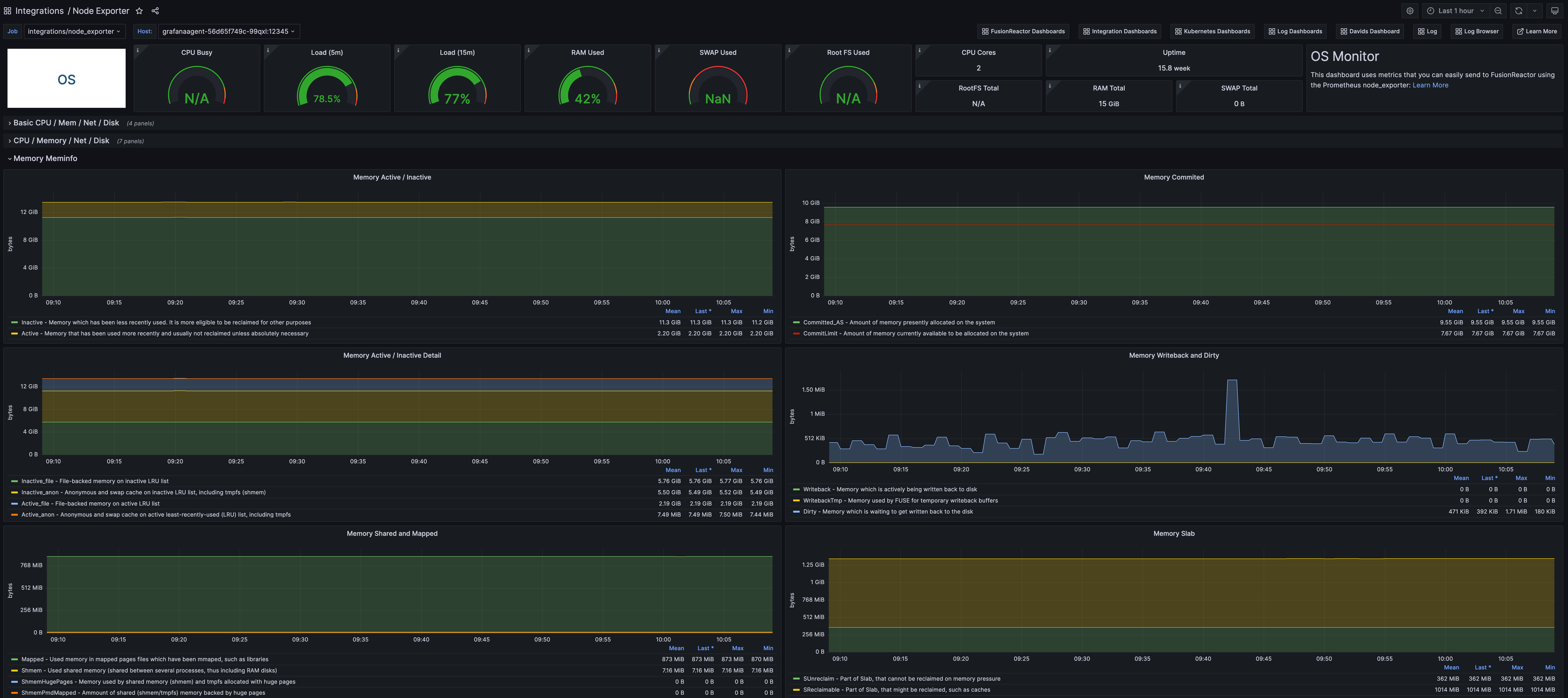
How do I ingest external data into FusionReactor
The Observability Agent is an innovative open-source tool designed to streamline the installation and configuration process for the Grafana Agent. Acting as a convenient wrapper, it automates the installation of the agent and performs a comprehensive scan of the services running on your machine. Leveraging this information, the Observability Agent seamlessly generates a configuration file with pre-configured integrations for the detected services. This eliminates the need for manual setup, simplifies the onboarding process, and enables swift integration of services with the Grafana Agent.
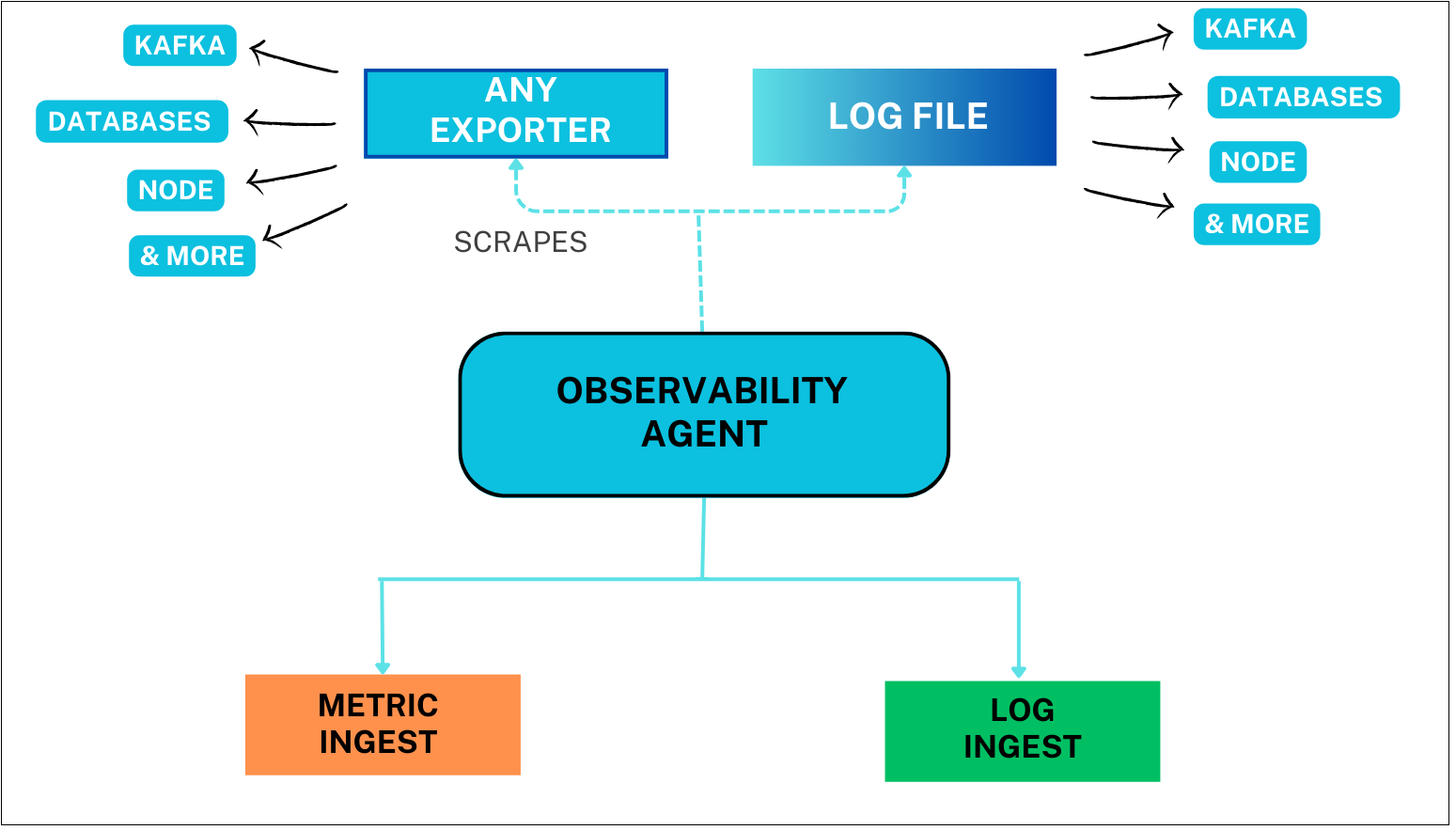
Installing the agent is easy, just follow these instructions and you will be ingesting external data in no time. If you are new to FusionReactor then start a free trial.
Leveraging Data Ingestion for Enhanced Performance and Comprehensive Observability with FusionReactor
Data ingestion from sources like Databases, Nginx, Kafka, Docker, IIS, and Machine System Metrics, in combination with FusionReactor, unlocks the potential for enhanced performance and comprehensive observability. By leveraging the power of data, organizations can make informed, data-driven decisions, identify optimization opportunities, and gain a competitive edge in today’s fast-paced digital landscape. Embrace the capabilities of FusionReactor’s data ingestion and embark on a journey of unlocking your system’s true potential.