

For many years the FusionReactor product documentation has been ran on a confluence server. We maintained our own server for many years and currently use the cloud version, but its never really been ticking all the boxes for our product documentation.
For each major release of FusionReactor we have a separate confluence space on the confluence cloud server. This allows users to see the documentation for the each version (excluding minor / bug fix releases) that the customer is running to ensure the screenshots are accurate.
The problem with having many copies of the documentation, for different version of the product, is that users don’t realize that they are reading documentation for the wrong version. This is not something which can be blamed on confluence but how we have been managing this system in the past. Google returns the search results which are most popular and as our 6.2.8 release was the newest release for the longest time, there has been a trend of people finding and using the docs from 6.2.8. Now its difficult for new releases of the documentation to be returned higher in googles search results.
This can be shown by googling forsite:docs.fusion-reactor.com crash protection
you get the following:
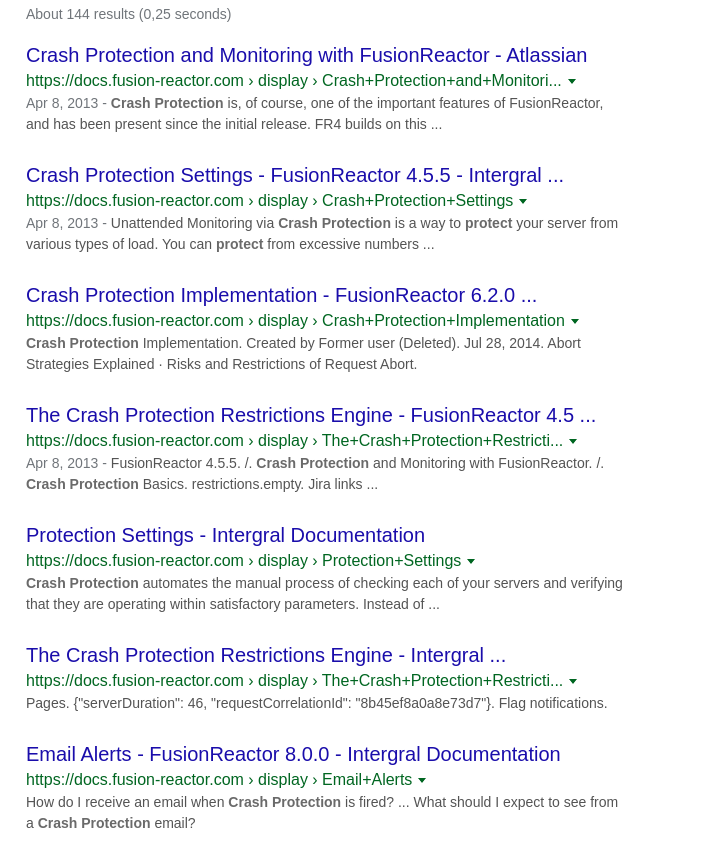
The image above shows that the actual page for FusionReactor Crash Protection hit doesn’t appear and the first FR 8 crash protection related page is the 7th search result and this is an 8.0.0 hit not 8.2.0. (results will vary from region to region). When google returns so many old versions before the newest FR version it causes customer confusion and impacts our support team.
Another major issue we had when updating documentation for a new release, was that we found it very difficult to update images. We had no idea if there was a screen shot of some UI component on a specific page, so we had to check every page we could find to update the screenshot based UI change.
We have been using markdown and mkdocs for some time in other areas of documentation (like the FR Cloud docs) so we knew that this worked but moving from confluence was not going to be automatic and we had not done this before.
First we needed to get the space content out of Confluence. You can do this by going to the confluence space, selecting “Space Settings”. Then under “Content Tools” there is an “Export” tab, which shows :

If you select “HTML” then “Normal Export” to get a HTML file per space page. Once you press “Export” the task will run and give you a zip file of the content to download.
We then converted all the html files to markdown
for i in *.html ; do echo "$i" && pandoc -f html -t markdown_strict -s $i -o $i.md ; done
We then use rename and mmv to rename the files to get them from filenames with a name like Weekly-Report_245548143.html.md to Weekly-Report.md.
Using following commands :
rename 's/.html.md$/.md/' * mmv '*_[0-9]*\.md' '#1\.md'
The following image shows how the html files were converted to markdown files. We can now delete the html files if we want.
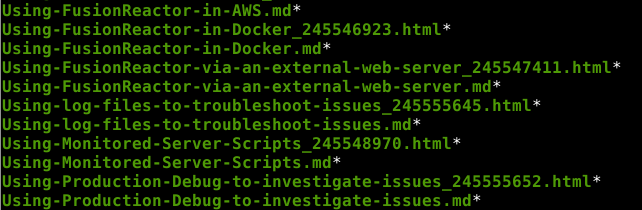
The renaming of files on disk also needs to be reflected in the markdown content. This was relatively simply using replace all with the same regex as we used with the mmv and rename commands.
We then setup the mkdocs and followed this mkdocs-material setup guide and made some customisation to use the FusionReactor icons and social links.

We managed to quickly get the docs running inside mkdocs as shown above.
The next problem we have going forward, before mkdocs actually replaces the current docs, is to update the documentation and fix it.
On our confluence versions of the docs we had lots of copy and paste content which was updated in one place and not another and we had a lot of broken links and out of date images.
We will continue to repair and improve our mkdocs over the next few weeks and months and then change the DNS entry.
Benefits of mkdocs
Below is a list of the benefits for mkdocs (as we see it) compared to our confluence documentation system.
- Ability to run automated tools against the docs.
- Allows checking of dead links.
- Automate spell checking and readability tools.
- Easy to find duplicate content and use markdown-include
- Ability to find and update images in a simply way.