

The situation is a common one when you’re a Java developer: you know there’s an application issue; you know it’s degrading performance and negatively impacting your customers; but you’re having trouble finding the root cause and you’re using valuable time that should be focused on the next deliverable. Today’s distributed application environments and architectures are more complex than ever and this only adds to the difficulty when trying to pinpoint software problems. In the recently published DZONE Guide to Performance & Monitoring, it was found that the most time consuming part of fixing performance issues is finding the root cause followed closely by being able to reproduce the performance issue.

The first tool most developers reach for when investigating problems are the application and database logs. Logs are an invaluable resource when looking for the key to an issue but searching through them takes time. They also might not give the developer a clear picture of what is causing the software to run slowly or throw exceptions. Many developers do not have access to production environments and often these logs are their only view into how the application is running. However, the logs may not contain the information they need or the logs may not even be available. Metrics are also useful but in many cases they don’t provide the kind of detailed information a developer can use to narrow in on the most likely cause of application slowness. It also takes time to collect and inspect all the data that might provide clues as to what is going on within the application. Is it a poorly written SQL query? A memory leak? A null pointer exception? It could be one or more of these issues and it may take hours or days to fully understand what is causing the problem.
Tweaking and adjusting the code for applications to make them run as efficiently as possible is important, but what do you do when something breaks without warning? Defects in code can be harder to locate than a performance issue because they occur much more infrequently and can be difficult to reproduce. Logs may show that an error occurred but if you don’t know exactly what the application was doing at that specific time under those specific conditions you may not be able to figure out what happened.
At this point you may be nodding your head because you’ve dealt with similar situations and have used the same procedures to address performance issues or come up with an emergency break-fix solution to get your application back up and running. Traditional application performance management (APM) tools provide some information and can be set to alert when something is wrong but they don’t give you the whole picture. This is where FusionReactor comes in with a whole new way to monitor your code and how it functions as it’s running in production. Instead of grepping through your logs, diving into the heap, tallying object instances, running stack traces over and over, guessing at some breakpoints, or including debug data into your code after an issue has arisen, FusionReactor allows you to interact and debug your production application as it is running. FusionReactor was designed to give developers the information they need along with powerful production-safe tools like the Production Debugger and the low-impact Profiler. This means that instead of spending time collecting data and attempting to reproduce the problem, you can look at your code as it executes to see where the problem starts and learn exactly what is causing the issue so that you can start to work on a solution as fast as possible.
[/column]
Developers have long been taught that debugging code while it’s running in production is a bad idea for many reasons including high overhead, having to spend time watching and waiting on the debugger while it runs, and the potential for a breakpoint to halt the entire application.
The FusionReactor uses JVMTI to bind directly into the built in debugger in the JVM, thus requiring no protocol overhead. The debug features are only enabled when the user wants to run them. The normal impact of having FusionReactor’s Debugger installed is zero (unless you use java 1.6.0._21 or earlier due to a bug in Java) apart from the memory used to load the library into memory.
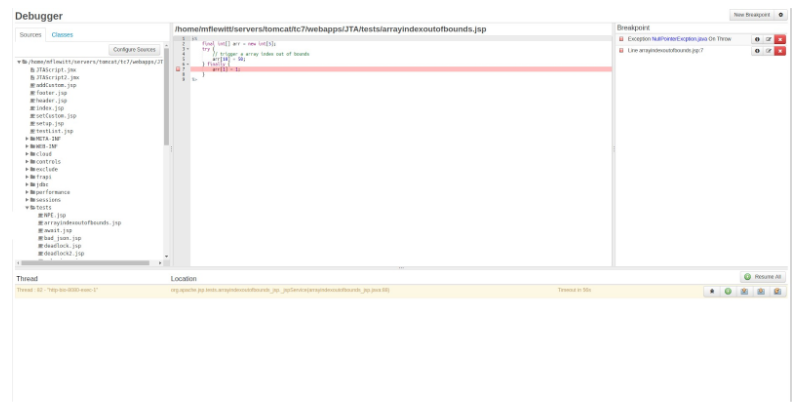
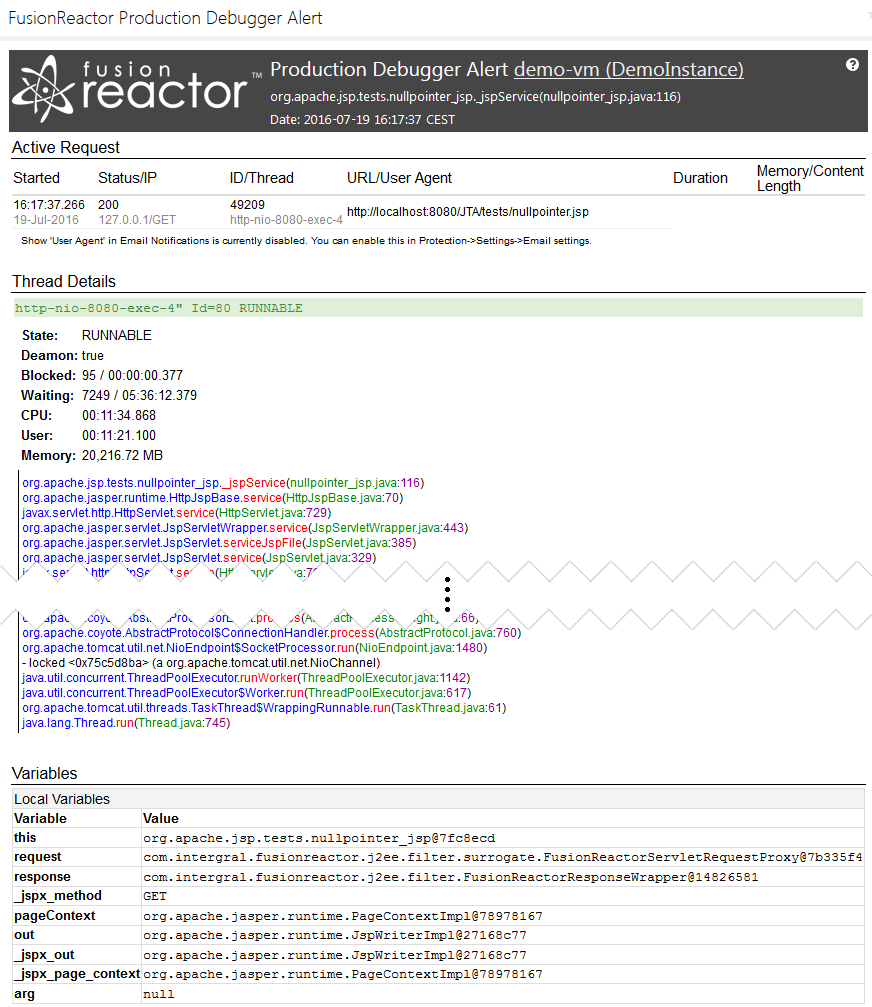
Typically, you would set a breakpoint then step through your code and wait for a breakpoint to fire. The point being, you need to actually attend to the debugger as it’s running, which is very time consuming. FusionReactor does away with this need, by sending out an email as soon as the breakpoint is hit. The email response can be configured one of two ways. In the first case, the breakpoint will fire, the stack trace and variable information is captured, and an email is sent to the developer. This is a non-invasive approach that allows the developer time to look at the data without any impact to the code running in production. In the second case, the breakpoint fires, stack trace and variable information is captured, and an email is sent however the thread where the breakpoint fired remains open for either a defined period of time or indefinitely, depending on how it has been configured. The developer can click on a link in the email which brings up the debugger at the point in the application where the breakpoint fired. So when some problem occurs at 3:00 am, FusionReactor will capture the state, capture the thread and essentially freeze it, until you come into the office and start debugging it.
[/column]
FusionReactor Debugger was designed with enhanced control mechanisms in mind to allow for safe production debugging:
- Set how many times a breakpoint fires so that only those threads are affected.
- Set a limit on the number of threads that can be paused in the debugger at any one time or how many threads a single breakpoint can pause.
- Set a parameter on how long a thread can be paused. Once the time limit has been reached the thread will be released to allow the end user to continue.
- Have a breakpoint send an email with the stack and variable information while it holds the thread for the predetermined time period.
It goes without saying that any production debugging should be done with caution so as not to affect other threads or the overall application, however FusionReactor’s Debugger allows you to target only what is needed to quickly investigate the issue.
The low-impact Java Profiler offers the ability to watch your code as it executes, enabling you to pinpoint bottlenecks in production. You can profile any request or transaction running on the JVM such as Tomcat, Glassfish, or Jboss. The Profiler can be run manually or configured to start when a particular condition has been set. This is a huge advantage in that you can leave the Profiler ‘on’ and set it to activate automatically when a request takes longer than expected instead of having to watch and wait for the event to happen. You can also limit the number of profile samples to control the accuracy of the sample. This information is then stored so that later you can drill down into the details to see how your code is running. The Profiler shows how much time is spent in each section of code as well as the overall percentage of it that makes up the transaction or request.
Performance tuning and troubleshooting will always be a part of development but hours or days of time spent searching through log files, running stack traces over and over, and trying to reproduce a production issue can be a thing of the past with FusionReactor. Being able to quickly solve issues results in less downtime, more stability, faster applications, happier customers, and less stressed developers!
To get start with a FREE trial of FusionReactor go here to Download FusionReactor and Start your trial.